
Cloud Guides Sending and Receiving SMS Messages
SMS Messaging
Aculab Cloud lets you communicate with your customers using SMS text messages. You can purchase telephone numbers and use them to send and receive messages.
Requirements
To send and receive messages, you need:
- A Production or Premium account - if you have a Developer account, please upgrade your account.
- A number on Aculab Cloud which has messaging enabled - to check this, view your purchased telephone numbers. If SMS is enabled you will have a green SMS icon. If the icon is red you can enable SMS by clicking it. If none of your numbers supports messaging, you will need to purchase one that does.
- A web server - so Aculab Cloud can tell you about status updates for your messages.
- Credit on your account - so you can buy a number and pay for your messages.
To receive messages, you also need:
- An Inbound Service for your number - which must be set up to handle messages. An Inbound Service tells Aculab Cloud how to handle incoming messages and calls to a particular number. First, view your Inbound Services. If you've not already created a Service for your number, click New and choose Telephone Number, then select one of your purchased telephone numbers and click Next. If you have a service already, just click your number in the list. Either way, once you have accessed the settings for the service, click the SMS tab and enter the Notification page. This is the URL of a page on your web server which Aculab Cloud will access to tell you when new messages arrive.
-
How it works
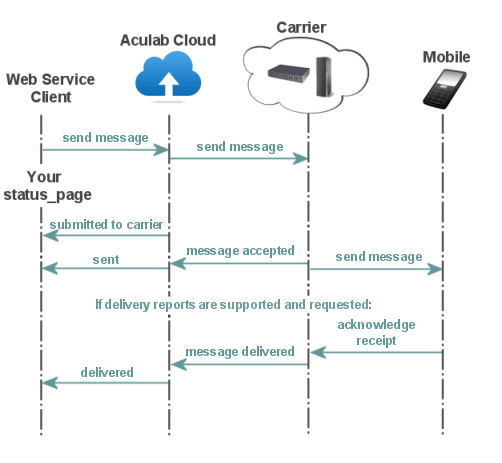
You pass the message to Aculab Cloud via the Managing SMS Messages Web Service. You can do this from your browser's address bar, call the appropriate function from one of our High-Level Language Wrappers or call it direct.
Aculab Cloud queues the message then submits it to a carrier and accesses your status_page to say that's done. The carrier accepts the message, sends it on towards the mobile phone, and Aculab Cloud accesses your status_page to tell you it's been sent.
If you've requested a delivery report and they're supported, the phone will acknowledge receipt, the carrier passes that on to Aculab Cloud, which accesses your status page to tell you the message has been delivered.
For more details
See Handling status updates for details of what is sent to your status page.
-
How it works
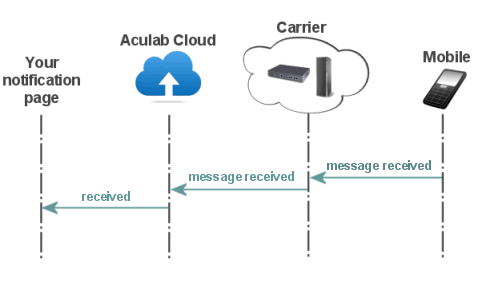
A mobile phone sends a message to your number. It is received by one of our carriers, which passes it on. It's received by Aculab Cloud, which accesses your notification page to give you the message.
How to receive messages
When messages are received on your numbers, you can choose to be notified via pages which you host on your web server. To make this work for one of your numbers:
- Check you've enabled messages (SMS) on that number by viewing your purchased telephone numbers. and ensuring a green envelope is displayed for the number. If a red envelope is displayed, click to change to green.
- If you've not already done so, create an Inbound Service for the number.
- Again if not done already, configure the number's Inbound Service by entering the URL of your web page on its SMS tab.
For more details
To see the content of what Aculab Cloud passes to your notification page, see Managing SMS Messages.
US-specific information
Aculab Cloud supports SMS on regular (10DLC) and toll-free numbers, as well as short codes. As part of the fight against SMS misuse, the sending of SMS messages to all US numbers is disabled by default. Please contact us so we can talk through your use cases and enable it for you.
Regular numbers (10DLC)
SMSs sent from Aculab Cloud regular numbers, termed 10 Digit Long Codes (10DLC), pass through Application to Person (A2P) routes. All use cases must be submitted in advance and agreed with The Campaign Registry, www.campaignregistry.com. This is something we will work to arrange for you. This approach provides the best reliability, as these routes are designed to handle A2P traffic and the carrier spam filters are aware of your use case. Messages sent and received via these routes generally attract carrier surcharges, which we will pass on without mark-up as an additional charge applied to your account.
Aculab Cloud maintains a list of opted-out numbers that our API prevents you from messaging. We automatically reply to opt-in, opt-out and help messages sent to your numbers. If you need the content of these messages to be changed from that shown below, please contact support.
Opt-in:
| Keywords | Default reply |
|---|---|
| START, YES, UNSTOP | You have successfully been re-subscribed to messages from this number. Reply HELP for help. Reply STOP to unsubscribe. Msg and data rates may apply. |
Opt-out:
| Keywords | Default reply |
|---|---|
| STOP, STOPALL, UNSUBSCRIBE, CANCEL, END, QUIT | You have successfully been unsubscribed. You will not receive any more messages from this number. Reply START to resubscribe. |
Help:
| Keywords | Default reply |
|---|---|
| HELP, INFO | Reply STOP to unsubscribe. Msg and data rates may apply. |
Toll-free numbers
SMSs sent to or from Aculab Cloud toll-free numbers pass through A2P routes where possible. All use cases must be submitted in advance and agreed with our carriers. This is something we will work to arrange for you, and applies to all SMS providers. This approach provides the best reliability, as these routes are designed to handle A2P traffic and the carrier spam filters are aware of your use case. Messages sent and received via these routes generally attract carrier surcharges, which we will pass on without mark-up as an addition made to your account. Also, these messages will usually be limited to a set number of Messages Per Second (MPS), dependent on use case and as agreed with our carriers.
Aculab Cloud maintains a list of opted-out numbers that our API prevents you from messaging. Our carriers automatically reply to opt-in and opt-out messages. We automatically reply to help messages sent to your numbers. If you need the content of that message to be changed from that shown below, please contact support.
Help:
| Keywords | Default reply |
|---|---|
| HELP, INFO | Reply STOP to unsubscribe. Msg and data rates may apply. |
Short codes
Aculab Cloud also supports exclusive and shared short codes. We will work with you to arrange the lease of a five or six digit short code, and to agree the use cases associated with it. Please contact us to learn more.
Cloud Guides Text To Speech
Text-To-Speech (TTS)
Aculab Cloud supports Amazon Polly and Cepstral Text To Speech (TTS) engines.
- Selecting a voice in the REST API
- Selecting a voice in the UAS API
- Using a Polly voice
- Using a Cepstral voice
- Reserved characters
- Text length
- Common SSML tags
- Charging
Selecting a voice in the REST API
In the REST API Play action, the text_to_say property supports Speech Synthesis Markup Language (SSML) allowing
you to change the way your text is spoken. However, this cannot be used to select the voice used by TTS
to say your text. This defaults to the voice configured in your service. You can choose a different voice
by setting tts_voice to a Selector from the voice tables below.
For example, to set English US Female Polly Kimberly use the following setting for tts_voice:
"tts_voice" : "English US Female Polly Kimberly"
Selecting a voice in the UAS API
In the UAS API, the Say methods support Speech Synthesis Markup Language (SSML) allowing you to change the way
your text is spoken, for example, by choosing which voice you'd like to use using the voice tag. You can
also choose the TTS engine to use, via the optional acu-engine tag which, if
provided, must be outermost in the string. If you don't provide these tags your account's Default TTS voice will be used.
For example, to set English US Female Polly Kimberly use the following SSML:
channel.FilePlayer.Say("<acu-engine name='Polly'><voice name='Kimberly'>I have something to say.</voice></acu-engine>");
Using a Polly voice
We support both Standard and Neural Polly voices. Standard voices synthesize lifelike natural speech that is suitable for many applications. Neural voices are enhanced through the use of deep learning technologies to deliver even more natural sounding speech. Pricing information for Standard and Neural voices is available on the Pricing page of your Cloud Console.
Polly's website has a demo which allows you to select a voice and immediately hear how different text will sound - see Polly demos.
Polly TTS supports a subset of SSML, which can optionally be embedded within the text you supply to the say function. For a summary of the SSML tags which may be used, see Common SSML tags below. For more detailed information, to go W3C SSML 1.1 recommendation.
We support the following Polly voices:
Using a Cepstral voice
Cepstral's website has a demo which allows you to select a voice and immediately hear how different text will sound - see Cepstral demos.
Cepstral TTS supports a subset of the Speech Synthesis Markup Language (SSML), which can optionally be embedded within the text you supply to the say function. For a summary of the SSML tags which may be used, see Common SSML tags below. For more detailed information, go to Cepstral SSML FAQ and scroll down to the 'Common Usage Examples'. With reference to that page, please bear in mind the following:
We support the following Cepstral voices:
| Name | Selector |
|---|---|
| Callie-8kHz (default) | English US Female Cepstral Callie |
| Vittoria | Italian Italy Female Cepstral Vittoria |
| Marta-8kHz | Spanish US Female Cepstral Marta |
We don't support:
- Inserting recorded audio files (our APIs' play functions already allow file replay)
- Applying Cepstral special effects
- Inserting bookmarks
Reserved characters
Some characters are reserved so, if the text you need to say contains any of these, replace them as shown:
| Reserved Character | Replace With |
|---|---|
| < | < |
| > | > |
| & | & |
| | | |
| ^ |
For example, "Bill & Ben played in the garden" would be become "Bill & Ben played in the garden".
Text length
The maximum length of the text to be converted is 1500 characters. As the length of the text is increased the generation time for the associated audio will also increase and, if is not a repeated phrase (and therefore may be cached) there will be a longer delay before the audio is played.
Common SSML tags
Polly and Cepstral both support a subset of SSML. Details of common tags can be found below. It is highly recommended that you test your application before deploying with a different TTS engine.
| Tag | Description |
|---|---|
| break | Inserts a break or pause in the speech. Optional arguments are time and strength. time sets an absolute value for the pause. For example <break time="3s"> and <break time="3ms"> set the break time to be three seconds and three milliseconds respectively. The length of a break may be up to 10 seconds in duration strength sets the relative value of the pause. These are none, x-weak, weak, medium, strong and x-strong. Examples: This is a <break /> sentence break. This is a <break time="2s"/> two second break. This is a dramatic <break strength="x-strong"/> break. |
| voice |
Allows the user to change the voice used. Parameter name is required, specifying the voice to use. The supported voices for each TTS are listed above.
This SSML tag is supported in the UAS API only. For the REST API please use the tts_voice setting.
Polly does not support using more than one voice in a request. The first voice tag will set the voice used for all the text.
Examples:
<acu-engine name='Polly'><voice name='Amy'>I'm using Amy instead of the default voice.</voice></acu-engine>
|
| prosody | Allows the user to change the pitch, speed and volume of a segment of speech. Common optional parameters are: pitch, rate and volume. pitch can be used to set the pitch of speech. Options are: x-low, low, medium, high, x-high,a relative change (measured in Hz) e.g. +50Hz, or a percentage change e.g +50%. rate sets the rate of speech. Options are: x-slow, slow, medium, fast and x-fast,a relative change (measured in Hz) e.g. +50Hz, or a percentage change e.g +50%. volume sets the volume for speech. Options are: silent, x-soft, soft, medium, loud and x-loud, a relative change (measured in Hz) e.g. +50Hz, or a percentage change e.g +50%. Examples: <prosody rate="x-fast">I'm using a very fast rate.</prosody> This is normal volume. <prosody volume="soft">This is a soft volume.</prosody> I can talk very <prosody rate="slow" pitch="low">deeply and slowly.</prosody> Today's date is the <prosody rate="-50%">15th April, 2012.</prosody> |
| emphasis | Can be used to read with empasis. Required parameter: level. Options are: reduced, moderate and strong. Examples: This is a <emphasis level="strong">level of emphasis</emphasis>, which can be used to highlight important information. |
Charging
Our TTS is charged per conversion, per minute with 15 second granularity. So, for example:
- A play action that plays for 12 seconds will be charged for 15 seconds.
- A get input action that plays a prompt of 5 seconds and then plays "I'm sorry I didn't catch what you said" which lasts 6 seconds and the 5 second prompt again will be charged for 30 seconds (5+6+5=16, rounded up to 2 periods of 15 seconds).
You can obtain detailed charge information for a specific call using the Application Status web service. You can obtain detailed charge information for calls over a period of time using the Managing Reports web services.
Cloud Guides Speech Recognition
Speech Recognition
Overview
Aculab Cloud uses Google Speech-to-Text, a multilingual natural language speech recogniser powered by machine learning. In practice, this means you tell it what language it'll be hearing then it will do its best to transcribe whatever you say to it. You can optionally provide hint information to adapt the recogniser to words or phrases which are more likely to be said.
In combination with Text To Speech (TTS), our Speech Recognition allows your application to present a natural, conversational interface to the user. This gives you much flexibility in how to drive the conversation, including the use of AI driven chatbots.
Our Speech Recognition is available for REST applications only, and requires REST API v2. It may be accessed using the get_input, play, run_speech_menu, start_transcription and stop_transcription actions.
Languages
Currently, our Speech Recognition supports 120 languages and language variants. For the up to date list, see Speech Recognition Languages.
Models
Google Speech-to-Text defines a number of models that have been trained from millions of examples of audio from specific sources, for example phone calls or videos. Recognition accuracy can be improved by using the specialized model that relates to the kind of audio data being analysed.
For example, the phone_call model used on audio data recorded from a phone call will produce more accurate transcription results than the default, command_and_search, or video models.
Premium models
Google have made premium models available for some languages, for specific use cases (e.g. medical_conversation). These models have been optimized to more accurately recognise audio data from these specific use cases. See Speech Recognition Languages to see which premium models are available for your language.
Use cases
Conversations
In most applications, the main action used to drive a conversation with the user is get_input. This allows you to play a file or TTS prompt, then receive a transcription of the user's response passed to your next_page. An example interaction might be:
- Prompt: "What would you like to do?"
- Response: "Pay a bill."
The run_speech_menu action, being somewhat more restricted, is ideal for menu driven applications. Here, a file or TTS prompt is played, and the user's response, which must be one of a set of specified words or short phrases, is passed to the selected next_page. An example interaction here might be:
- Prompt:"Would you like to speak to Sales, Marketing or Support?"
- Response: "Support"
Play with selective barge-in
The play action seems at first sight an odd place to feature Speech Recognition. However, consider the case when the user is listening to a long recorded voicemail. They may say a small number of things to stop it, for example "Next", "Again" or "Delete" but, with it being a long voicemail, there is always the chance of the Speech Recognition transcribing some background speech. The play action allows the application to specify whether barge-in on speech is allowed and, if so, whether it is restricted to specific supplied phrases.
Live transcription
The start_transcription and stop_transcription actions allow your application to receive a live transcription, sent to their chosen page, of the speech on any combination of the inbound and outbound audio streams, all performed outside the ongoing IVR call flow. These actions would typically be used to allow the application to be aware of and react to the content of human to human conversations. For example, a section of the agent or receptionist's screen may update to display a 'Book an appointment' button if the caller mentions they'd like to. Alternatively, the manager's screen may update to flag while an agent is involved in a particularly difficult conversation.
Live translation
The connect action can be configured to include an AI translator in the conversation. The translator will use TTS to say translations of the speech recognized from each user to both parties.
Speech adaption
When starting speech recognition, as well as specifying the language, the application may optionally provide a set of words or phrases, word_hints, to adapt the recognition to what is more likely to be said. This reflects the fact that very few conversations are open ended - the application generally has some prior knowledge of the speech it is expecting to receive. For example, when asking the caller to pick a colour, including "aquamarine" in the word hints will make the recogniser more likely to transcribe that than "aqua marine". Similarly, when asking the caller to say a digit, providing a set of word_hints comprising all the digits will improve the accuracy of the transcription.
Note that, in spite of the above, our Speech Recognition is not a grammar based speech recogniser. So, for example, you can't constrain its output to be four digits, a time or a date. However, armed with word_hints and some post processing of the transcription, it can allow very natural, expressive dialogues and is well matched to the increasingly human-like conversations of modern AI chatbots.
Charging
On a trial account you can start using Speech Recognition straight away.
For other accounts, our Speech Recognition is charged per recognition, per minute with 15 second granularity. So, for example:
- A get_input which listens for 12 seconds will be charged for 15 seconds.
- A start_transcription for separate outbound and inbound audio which listens for 3 minutes 20 seconds will be charged for 7 minutes (each of the two transcriptions is charged for 3 minutes and 30 seconds).
You can obtain detailed charge information for a specific call using the Application Status web service. You can obtain detailed charge information for calls over a period of time using the Managing Reports web services. When using transcription in Separate mode there will be two corresponding entries in the Feature Data Record (FDR), one for each direction.
Cloud Guides File Availability
Media File Availability
Aculab Cloud accesses files via a highly reliable, distributed storage system. The way it works will generally be transparent to you as an application writer, but there are a few important things to bear in mind:
- When an application completes a record, the recorded file will be available for use immediately in that application, and generally within a few seconds in other applications, from cloud.aculab.com and from the Web Services API.
- When an application receives a fax, the same applies to the received tif file.
- When uploading a new file via cloud.aculab.com or the Web Services API, it will generally be available for access within a few seconds.
- When deleting or overwriting an existing media file via cloud.aculab.com, the Web Services API, or the UAS API, the change generally takes several seconds to become available across the distributed storage system. Until this has been accomplished the available file may be the old version. So, scenarios that require quick access to newly written files should write to new filenames rather than reusing old ones.
Cloud Guides Protocols and Formats
Protocols and formats
Call codecs
Calls are controlled using the Session Initiation Protocol (SIP). Telephone calls are routed through SIP-to-PSTN gateways at our inbound and outbound providers. Call media is transported using the Real-time Transport Protocol (RTP). Within RTP, Aculab Cloud supports the G.711 A-law and G.711 mulaw audio codecs, and RFC2833 DTMF digits - all sampled at 8000Hz.
G.729 is available on request. Contact us if your need to use this codec with your provider.
Media file formats
REST API and UAS API applications can play media files that have been uploaded to an account's media file storage on Aculab Cloud. Similarly they can record media files to an account's media file storage.
Aculab Cloud plays and records Microsoft wav format (.wav) media files compressed using:
- G.711 A-law (default)
- G.711 mu-law
- OKI ADPCM
- IMA ADPCM
- signed 16-bit PCM
- unsigned 8-bit PCM
Only single channel or mono recordings are supported.
G.711 A-law or G.711 mu-law are preferred since they are reasonably small and provide the best quality for telephony use.
The supported sampling rates are:
- 8000Hz (default)
- 6000Hz
- 11000Hz
- 11025Hz
8000Hz is preferred since it matches the sampling rate used on calls and therefore provides the best quality.
Media files matching this specification can be uploaded to Aculab Cloud via the File Management web service or the File Management page.
Fax file formats
REST API and UAS API applications can send fax files that have been uploaded to an account's media file storage on Aculab Cloud. Similarly they can receive and save fax files to an account's media file storage.
Fax files to be sent or that are received are stored in the Tagged Image File Format (.tif).The compression schemes supported are:
- CCITT Group 3 1-Dimensional Modified Huffman run length encoding (RLE). Also known as MH or CCITT 1D.
- CCITT T.4 bi-level encoding as specified in section 4, Coding, of ITU-T Recommendation T.4. Also known as MR2D, CCITT Group 3 fax encoding or CCITT Group 3 2D.
- CCITT T.6 bi-level encoding as specified in section 2 of ITU-T Recommendation T.6. Also known as MMRT6 or CCITT Group 4 fax encoding.
These compression schemes do not support colour or greyscale. Images are black and white only.
The page widths supported are:
- A4 (1728 pixels, 21.95cm)
- B4 (2048 pixels, 26.01cm)
- A3 (2432 pixels, 30.89cm)
See Sending & Receiving Faxes for more details.
Media files matching this specification can be uploaded to Aculab Cloud via the File Management web service or the File Management page.
Categories
Archive
-
2024
- May 2024 (1 article)
- April 2024 (1 article)
- March 2024 (2 articles)
- January 2024 (1 article)
-
2023
- October 2023 (1 article)
- August 2023 (1 article)
- June 2023 (1 article)
- March 2023 (1 article)
- February 2023 (1 article)
-
2022
- December 2022 (1 article)
- November 2022 (1 article)
- October 2022 (1 article)
- September 2022 (1 article)
- August 2022 (1 article)
- June 2022 (2 articles)
- January 2022 (2 articles)
-
2021
- December 2021 (1 article)
- November 2021 (3 articles)
- October 2021 (1 article)
- August 2021 (2 articles)
- July 2021 (2 articles)
- June 2021 (1 article)
- April 2021 (1 article)
- March 2021 (3 articles)
- January 2021 (1 article)
-
2020
- October 2020 (2 articles)
- September 2020 (1 article)
- August 2020 (1 article)
- June 2020 (1 article)
- May 2020 (1 article)
- April 2020 (5 articles)
- March 2020 (2 articles)
- January 2020 (1 article)
-
2019
- November 2019 (2 articles)
- September 2019 (1 article)
- August 2019 (1 article)
- July 2019 (1 article)
- May 2019 (5 articles)
-
2018
- September 2018 (1 article)
- May 2018 (1 article)
- March 2018 (1 article)
- January 2018 (3 articles)
-
2017
- September 2017 (1 article)
-
2016
- December 2016 (1 article)
- November 2016 (1 article)
- October 2016 (1 article)
- June 2016 (1 article)
- March 2016 (1 article)
- February 2016 (1 article)
- January 2016 (1 article)
-
2015
- December 2015 (1 article)
- November 2015 (1 article)
- October 2015 (2 articles)
- September 2015 (2 articles)
- August 2015 (2 articles)
- May 2015 (2 articles)
- April 2015 (1 article)
- March 2015 (2 articles)
- February 2015 (3 articles)
- January 2015 (2 articles)
-
2014
- December 2014 (3 articles)
- November 2014 (3 articles)
- June 2014 (1 article)
- January 2014 (1 article)